Priority inversion issues in multithreaded job systems running on heterogeneous CPU systems
Introduction
This post is about a bug in Unity job system that was found while I was working on the Burst masked occlusion culling. However, another issue which is described here is much more global and significant; it is what I call “priority inversion in multithreaded job systems”.
The short version of the issue comes as follows: a job is on the critical path, and the application is waiting for it to finish on a job system thread. Then this critical job is being neglected by the operating system - either by scheduling it on a slow CPU core, or by interrupting the job and giving the CPU to low-priority tasks. In the end, it leads to sporadic delays that are especially noticeable in games.
I discovered this issue quite a long time ago while profiling performance spikes on Android. Mobile devices are much more susceptible to multi-threaded priority inversion for a number of reasons; first, the OS (CPU governor) tries to conserve battery by aggressively clocking down CPU cores or even shutting them down. I will show effects of this later. Second, Arm mobile CPUs use big.LITTLE (plus DynamIQ and more recent developments) architecture for more than a decade because it helps save battery and improve CPU thermal conditions - a great and proven technology. But it also means that the OS wants to prioritize running loads on little CPUs; if a critical job appears on such a core, it may mean missing frame presentation deadline.
Newer Intel CPUs implement a similar technology (Intel Hybrid with P- and E-cores), and Apple also has had P- and E-cores for quite some time. I anticipate that they may suffer from a similar problem, however I have seen most reports from Android+Arm CPUs; I can only guess that maybe the performance difference between big and little cores is much bigger on Android, especially that big cores became really powerful with the introduction of Cortex X-series.
The Job System profile
The device that was profiled is a Samsung Galaxy S22; it has a single Cortex X2 core (big), three Cortex A710 (medium) and four Cortex A510 (small cores, mostly unused by Unity).
The systrace revealed a very curious issue with job scheduling. Here are the screenshots. Please forgive my touchpad drawing skills and ignore the curvy yellow marker.
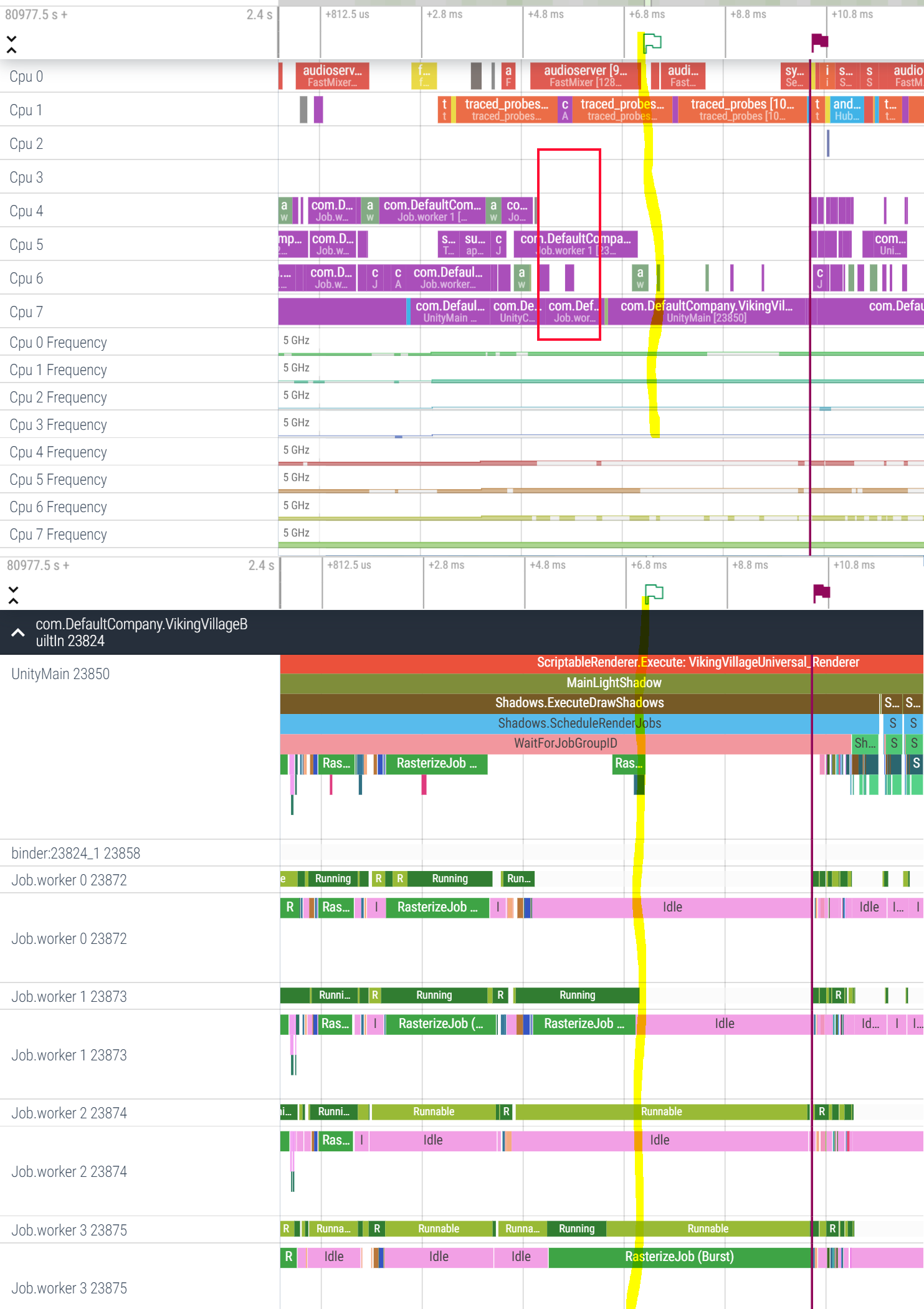
In the upper part of the picture, Cpu4-6 are Cortex A710, Cpu7 is Cortex X2.
Let’s take a look at it at about +5.8ms timestamp, in the red box.
Cpu4 seems to be offline.
Cpu5 is executing Job worker 1 thread.
Cpu6 is mostly idle, with few short bursts of some high-priority workload.
Cpu7 was running Job worker 3 thread, which was executing RasterizeJob, which is on the critical path.
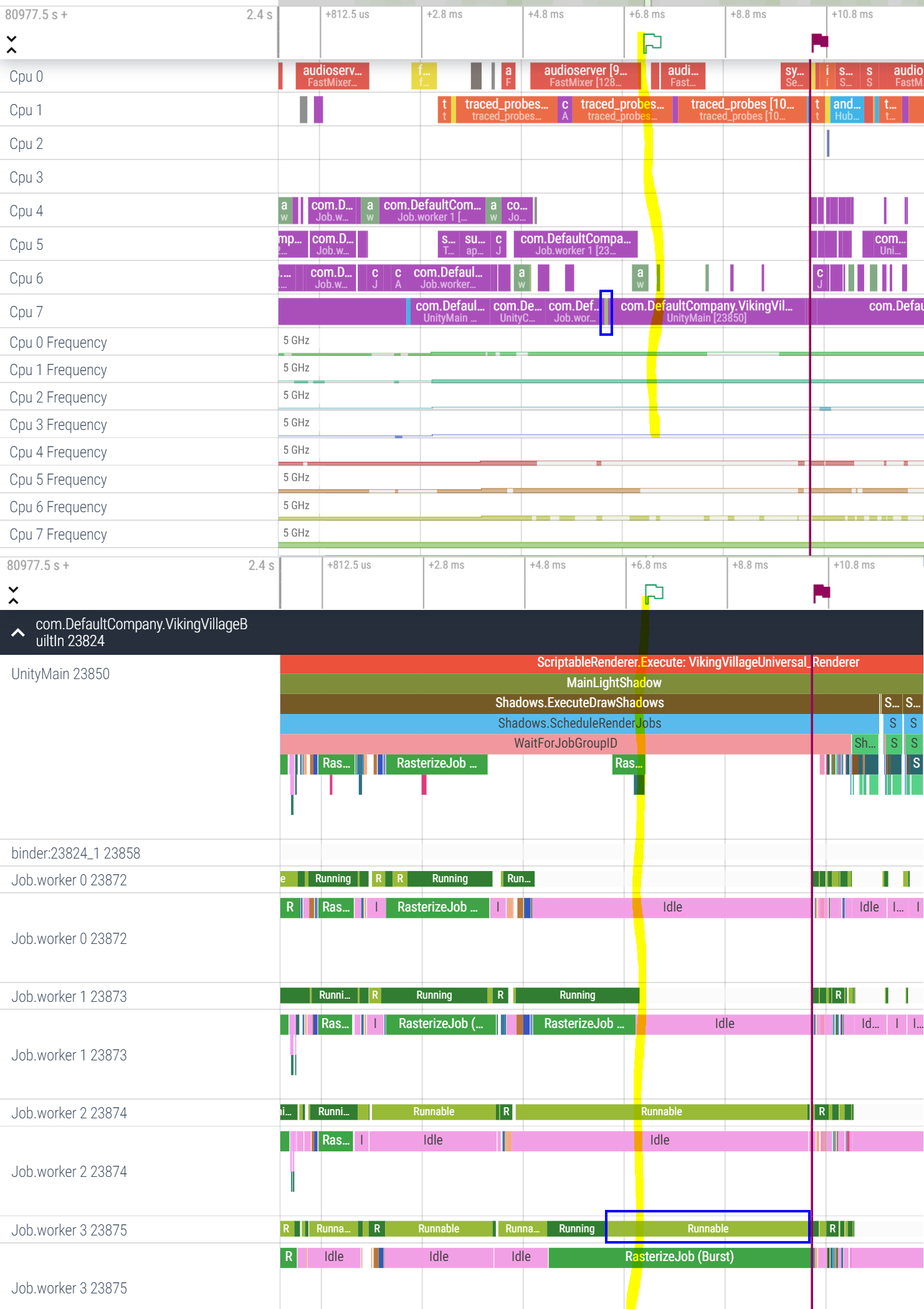
Around +6.4ms timestamp this thread is preemtped by something very important (audio?) which runs on Cpu7 for a tiny fraction of time - see the tiny light-green box highlighted in a blue box. If you look at the bottom part, at the same moment in time you can see that the status of Job worker 3 thread changes from Running to Runnable (blue box).
A thread in Runnable state is not waiting on anything and is ready to execute. It is just waiting for its turn. The Scheduler decides when to give this thread some CPU time.
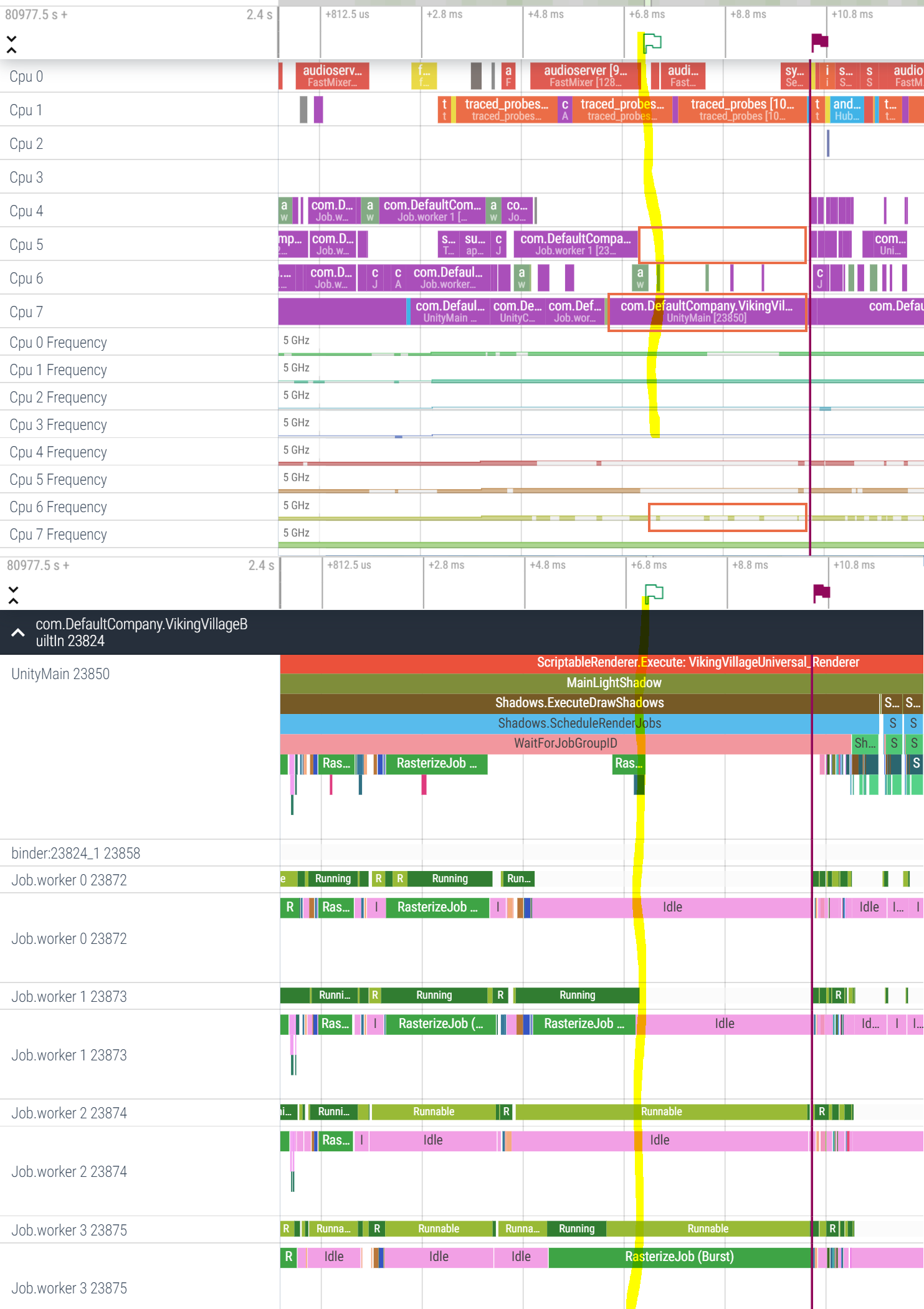
After executing this VIP thread, the Completely Fair Scheduler decides it wants to give UnityMain thread a chance to run on Cpu7. (remember: Job worker 3 thread is Runnable. It is not waiting on a semaphore, but ready to run if the scheduler picks it) - see the orange box.
Soon, Cpu5 completes its RasterizeJob on Job worker 1 thread and goes offline (remaining two orange boxes).
At this point of time, we have only one core online and capable of running user code - Cpu7 (there are tiny bursts of activity happening on Cpu6 but it goes offline immediately thereafter). It is not entirely clear why this is happening… I can only speculate that due to overheating, the CPU governor has shut down the whole cluster of Cpu4-6 (or put them to a lower power state). Why didn’t it shut down Cpu7 which is the hottest and the hungriest (Cortex X2) - is unclear. I don’t think the shutdown happened to save the battery, for the same reason. Overheating is most likely.
The Job System issue
So, Cpu7 switches to executing UnityMain.
The job system identifies another tiny instance of RasterizeJob in the queue, and asks UnityMain to pick it up. So it does, executes this tiny job (bottom part of the picture, green box).
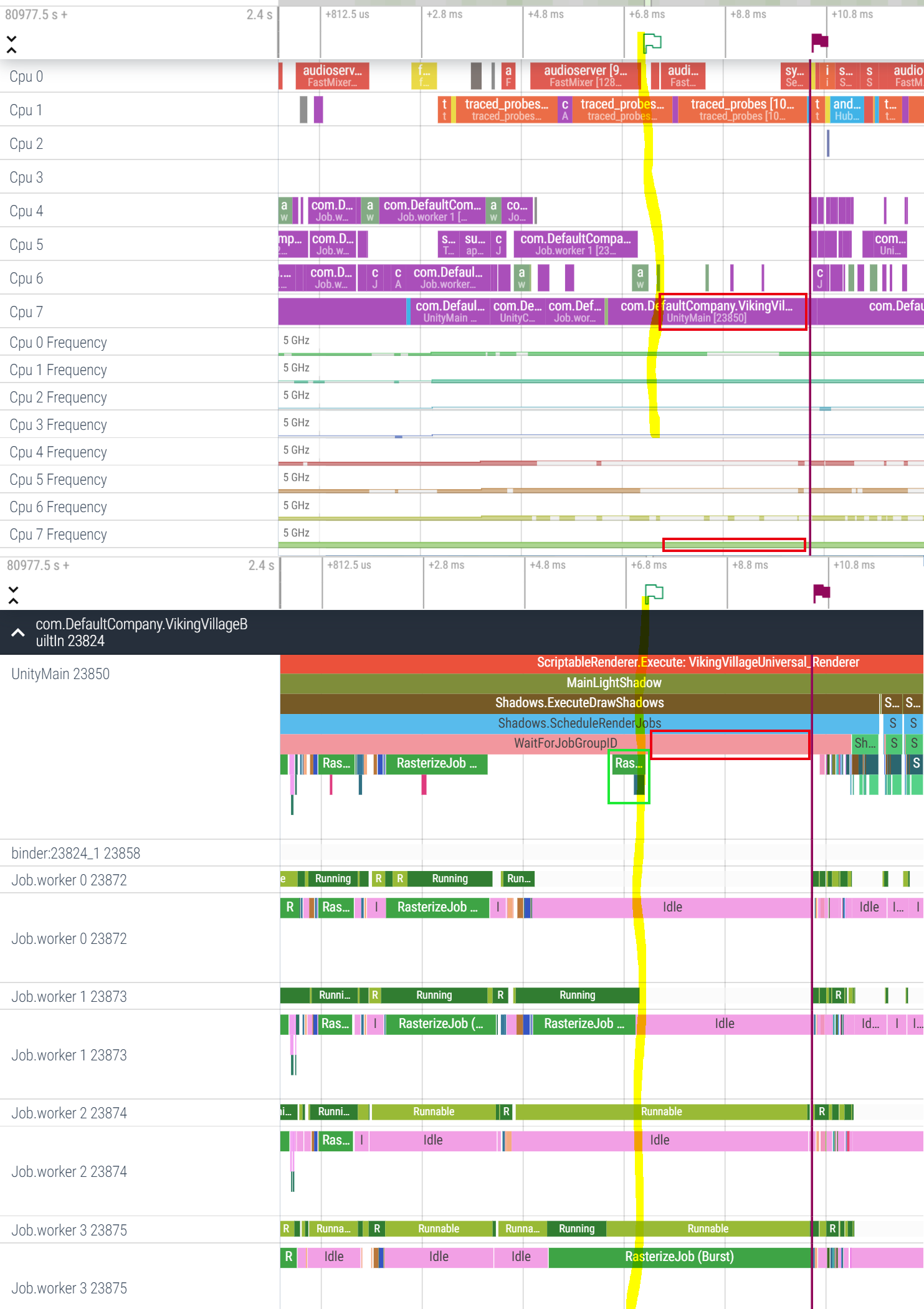
Up to this point, everything is more or less okay.
Now comes the darkness.
UnityMain still waits for all RasterizeJobs to finish before it can do something else.
At this point, a 2ms long WaitForJobGroupID happens on the UnityMain thread (see three red boxes), which runs (!!!) on the single available core clocked at max speed (!!!), waiting for the job on Job worker 3 to complete, which in its turn waits for an available core to run on.
It looks like a busy wait for me, but a too lengthy one.
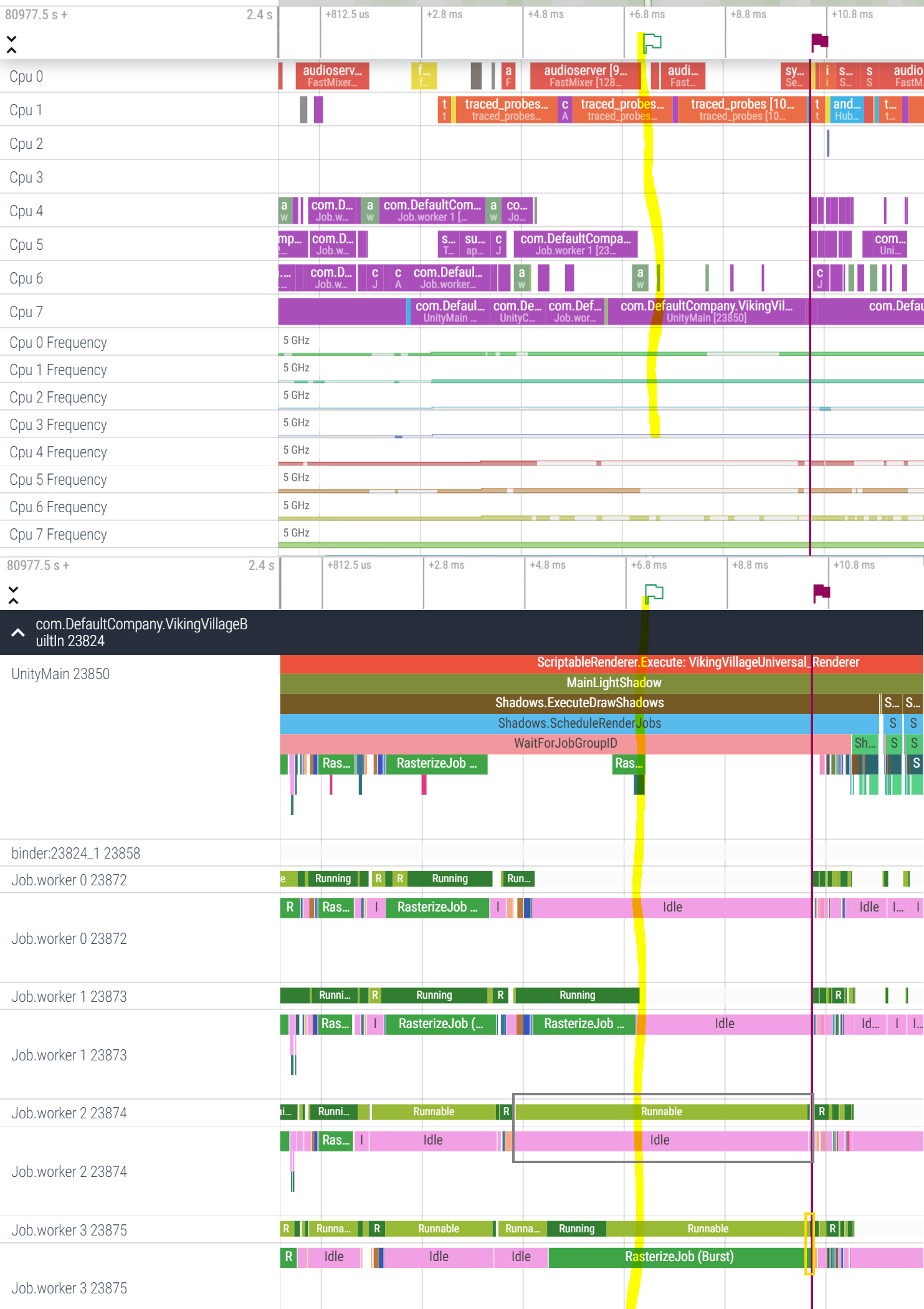
When the busy wait is over, Cpu7 picks up the remainder of the RasterizeJob that has started on Job worker 3, and finishes its chunk of work in literally no time (tall and narrow yellow box). Cpu4-6 wake up, and the system continues in a normal way.
This busy wait was clearly an issue in the Unity job system, and it has been fixed; it’s no longer busywaiting in situations like the above. But getting into such an unfavourable state at the first place is not a good thing.
If you looked at the screenshots carefully, you may have noticed that the situation with the task on Job Worker 2 was even more dramatic. It’s marked with a grey box on the picture above. Now let’s see the details:
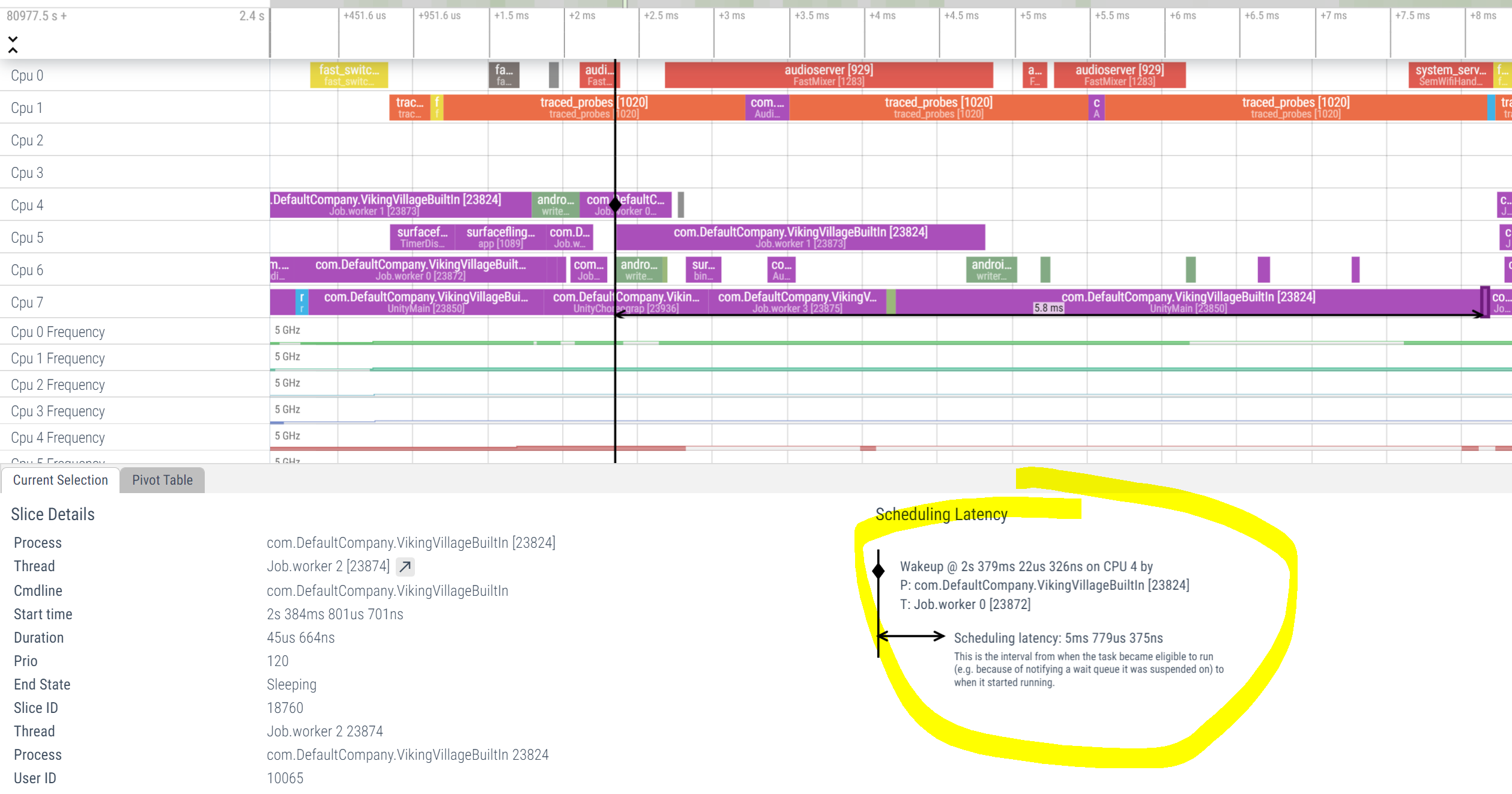
A job that lasted less than 46 microseconds (!!) to complete, took more than 5 milliseconds (!!!!) to get scheduled to run. And this is not because of an issue in the job system, but rather because there were merely no active cores to run the thread.
The Priority Inversion
First case:
- you have
thread1which runs a load that is on the critical path - this thread gets pre-empted (interrupted) by
thread2, which does something long but not that important - when the
thread2is done (or the scheduler window is over), the system may get back tothread1… or may not do so. - the less cores you have available in the system, the worse the effect. (and you have little control over that!)
- spawning more worker threads may make things worse too. I often heard advice from our platform partners that we should spawn more threads and let the OS handle it
 . However, the more threads are there, the more pre-emtping is going to happen. Please remember that cores may come offline, so we have even more threads for even less CPU cores.
. However, the more threads are there, the more pre-emtping is going to happen. Please remember that cores may come offline, so we have even more threads for even less CPU cores.
Second case: There is a subtype of such priority inversion instances where the load on the critical path gets scheduled on a slow little core, while the big cores are busy doing non-critical work because the queue of threads to run is not empty. In theory, if the code on the critical path loads CPU enough, the governor should quickly migrate the thread to a big core… but in practice, I’ve seen such priority inversion cases causing nasty slowdowns and glitches. This is one of the reasons why Unity is currently NOT using little cores to run critical threads like UnityMain, Gfx device worker thread or Job worker threads.
Unfortunately I haven’t got any systrace screenshots to show this second case happening right now.
Solution..?
I have showcased two possible cases of priority inversion above, and they cause noticeable glitches, especially in games where meeting frame deadlines is crucial.
How did we try to solve the issue?
Changing thread priorities does not really help. First of all, you can’t really change thread priorities in user space on Android (you can change niceness though). There are always threads of higher priority class (SCHED_FIFO and SCHED_RR) that will interrupt your threads once they need to run. Second, you don’t want to make ONLY job worker threads higher prio. Main, Gfx and Job Worker threads should have the same priority, otherwise other side effects will appear.
In the end, we decided to exclude small cores from running UnityMain, Gfx worker and Job Worker threads. Thread affinity for those is being set to medium and big cores. This reduces nasty issues of critical threads ending up on a small core clocked at 300Mhz for a timeframe of several milliseconds. This decision is quite old and had caused issues when the core detection algorithm fails on a new SoC, leaving only 2 cores in use instead of 4 or even 6.
We also added some complicated logic to decide the number of threads to spawn, as well as to scale them against the number of active (online) cores.
Since then, many improvements have happened to the Linux scheduler and Android code, like the Energy Aware Scheduling. I suggested several times that we remove the thread affinity and let the OS scheduler decide, and then work with all stakeholders (Google, Arm and phone manufacturers) to fix issues, but it was not implemented due to high risk of immediate regressions.
I think the roots of the issue lay within the CPU scheduler and governor being not perfect. They need a workload to last for something like a millisecond (or maybe a few) to decide whether to clock up the core or even to move the thread to a beefier core, and this makes sense; migrating a thread because of shorter bursts is less efficient. Maybe if the scheduler could deduce that this thread is waiting for another one to finish, and take this into account when scheduling, even to a point when there is a tree or a graph of thread dependencies maintained, that could help. On the other hand, the application (game) could provide such dependencies to the scheduler to make its job easier. To be honest, I don’t know if such a suggestion is viable from implementation point of view.
The priority inversion is one of the issues that is typical to modern heterogeneous CPU systems running multi-threaded workloads, especially on mobile devices. It may cause visual glitches in games because of missed frame presentation deadlines. If looking on a retail device and userspace, the mechanism is quite opaque, because much of what’s happening in the OS kernel (CPU scheduler and governor) is a black box. It also shows that simple extensive solutions like “spawn more threads” don’t really work, and a performant and power efficient system is complicated to implement. A robust solution can only emerge from combined effort of the platform owner (Google Android), CPU designer (Arm), Linux kernel developers, game engine and game developers.