Hashing, IL2CPP and LLVM bug Investigation
Hashing, IL2CPP and LLVM bug Investigation
When working on the Android NDK upgrade, I stumbled upon 26 red tests related to hashing in one of our test suites. Here’s an example:
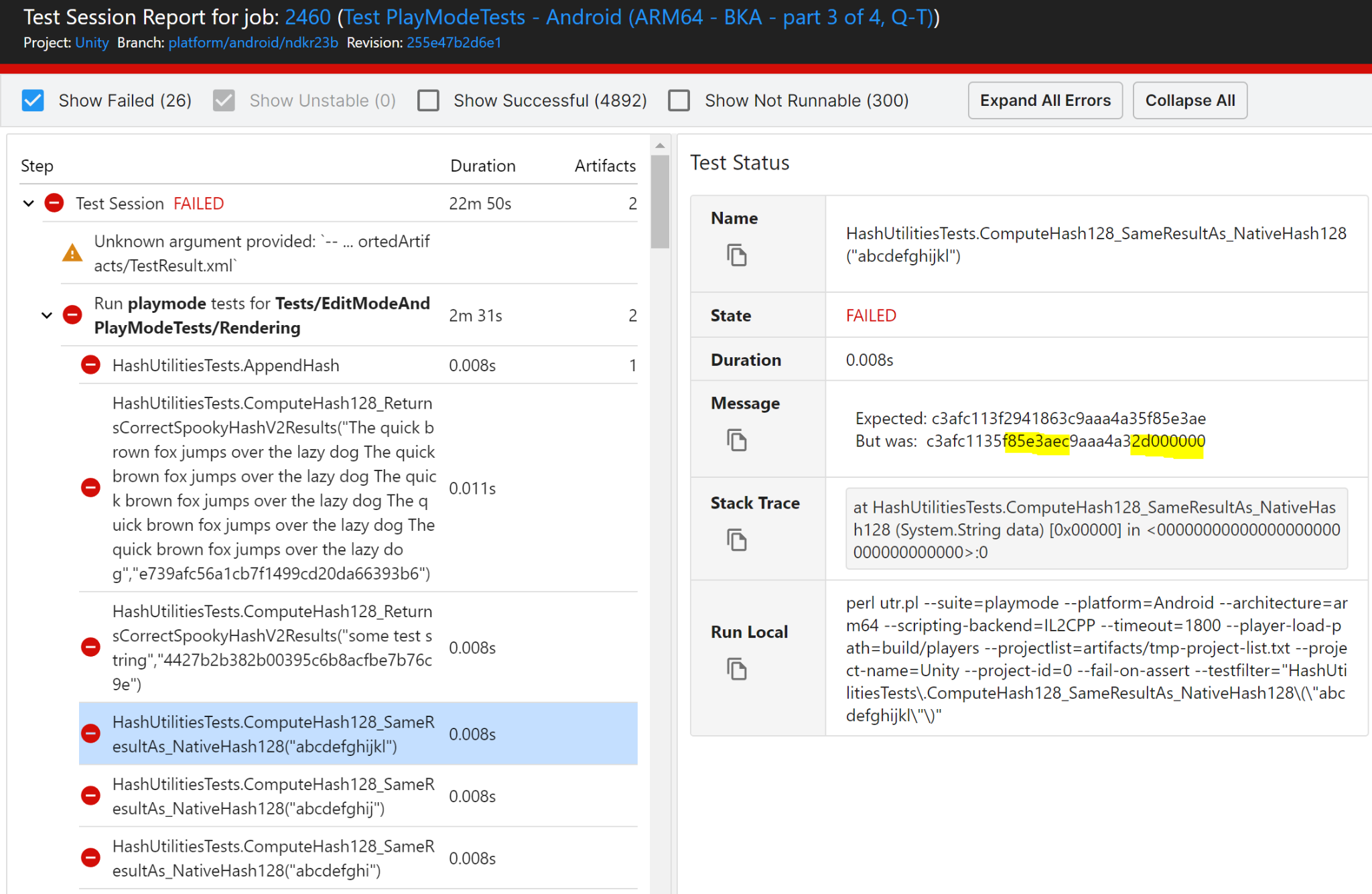
Important points which can be concluded by just looking at the CI and the test report:
- Fails only when run on Android;
- The failure doesn’t happen on trunk, but happens on the branch where Android NDK is the only change;
- Armv7+Mono tests are green, however Arm64+IL2CPP are red;
- The hash value is obviously incorrect; out of 128 bits, the second and fourth 32-bit blocks are wrong (highlighted in yellow) – compare to the reference hash value in the “Expected” field;
- We have native and managed hash implementations in Unity, and this is the managed hash value which is incorrect, the native equivalent is correct.
For those who aren’t familiar: IL2CPP is a technology which takes C# IL and translates it into C++ code. The transformation pipeline looks something like this:
C# => (IL2CPP) => C++ => (compiler, clang) => native code
A logical conclusion is that something in this chain is broken, because the same managed code compiled with Mono works correctly.
Let’s check the first step in the chain. Having compared the IL2CPP output (.cpp files) on trunk and the NDK upgrade branch, I confirmed that the C++ code is the same. Not unexpected, but important. Now we’re left with the right part of the chain:
C++ => (compiler, clang) => native code
Let’s look at one peculiar test which fails:
[Test]
public void Hash128_u64_properties_are_valid()
{
{
var hash = new Hash128(1L, 2L);
Assert.AreEqual(1L, hash.u64_0); // this line fails
Assert.AreEqual(2L, hash.u64_1);
}
{
var hash = new Hash128(1, 2, 3, 4);
Assert.AreEqual(1L | 2L << 32, hash.u64_0);
Assert.AreEqual(3L | 4L << 32, hash.u64_1);
}
}
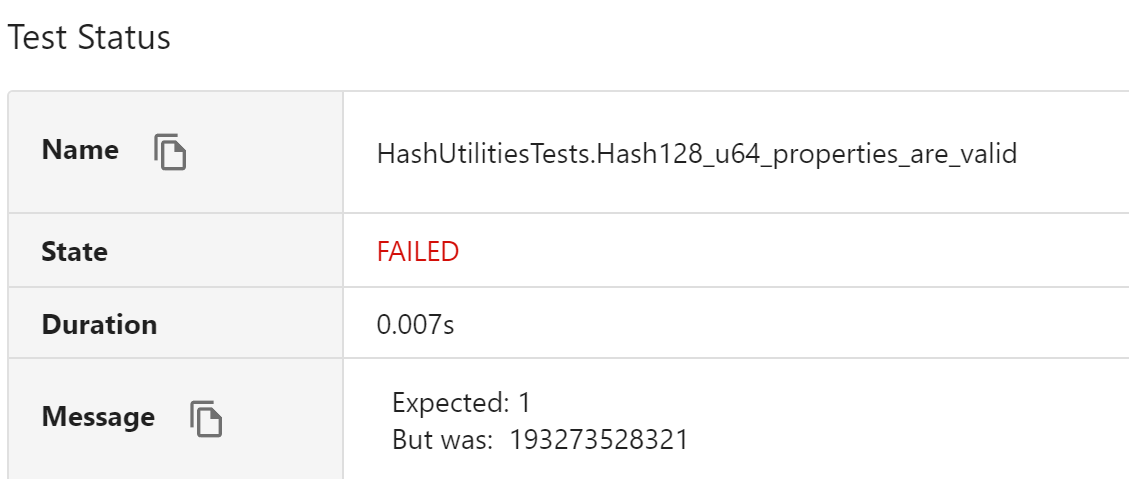
How on Earth can this happen?!
Interesting fact: the actual hex result is
0x2D00000001. So the lower 32bits are correct, but the higher ones get some garbage in.
The Investigation
Let’s look into the Hash128 implementation:
public Hash128(ulong u64_0, ulong u64_1)
{
var ptr0 = (uint*)&u64_0;
var ptr1 = (uint*)&u64_1;
m_u32_0 = *ptr0;
m_u32_1 = *(ptr0 + 1);
m_u32_2 = *ptr1;
m_u32_3 = *(ptr1 + 1);
}
uint m_u32_0;
uint m_u32_1;
uint m_u32_2;
uint m_u32_3;
internal ulong u64_0
{
get
{
fixed(uint* ptr0 = &m_u32_0) return *(ulong*)ptr0;
}
}
internal ulong u64_1
{
get
{
fixed(uint* ptr1 = &m_u32_2) return *(ulong*)ptr1;
}
}
The code uses unsafe pointer magic, but it all looks correct at a glance. However, it’s obvious that either the constructor or the u64_0 property is doing the wrong thing.
Let’s dive into the favourite part:
The assembly
The getter property implementation is the same for trunk (uses NDK r21d) and NDK r23b branch:
Hash128_get_u64_0_mCA2981F425AAD6F5E10415DFF3F484E931FCC507:
10abe48: 00 00 40 f9 ldr x0, [x0]
10abe4c: c0 03 5f d6 ret
Looks neat and logical, just returns *this (passed as input param in x0) casted to 64-bit.
Let’s look at the constructor then.
r21d:
>>> stp x2, x1, [sp, #-16]!
str w1, [x0]
ldr w8, [sp, #12]
stp w8, w2, [x0, #4]
ldr w8, [sp, #4]
str w8, [x0, #12]
add sp, sp, #16
ret
r23b:
>>> sub sp, sp, #16
str w1, [x0]
ldr w8, [sp, #12]
stp w8, w2, [x0, #4]
ldr w8, [sp, #4]
str w8, [x0, #12]
add sp, sp, #16
ret
The only instruction which differs is highlighted here.
In r21d version, two input params are saved onto stack, and after the store stack pointer gets 16 bytes subtracted.
In r23b version, input params are not saved onto stack at all! The stack pointer gets 16 bytes lower though.
The rest of the code is storing values into fields of Hash128 in 4 byte blocks. However, the code which stores into m_u32_1 and m_u32_3 gets values from the stack, and the values in the stack are not initialized in r23b case! Basically, it writes garbage from the stack into high 32bits of each of 64-bit halves of Hash128.
This explains why we get hash results which are incorrect in places of m_u32_1 and m_u32_3.
This behaviour on its own is quite dangerous because memory is initialized with some random value from the stack – a potential security breach. I’m so happy these tests are in place!
Here’s a godbolt link with some code extracted from IL2CPP generated .cpp. I also got an explanation from our friends at Arm that the store is removed by DSEPass which is likely caused by casting the address of a 64-bit unsigned value to a pointer to 32-bit unsigned (which is an undefined behavior).
The Fix
First of all, I wouldn’t blame IL2CPP for its codegen because, to be honest, the original C# code contains the undefined behavior too. Fixing IL2CPP codegen is a dangerous change that I’d rather avoid.
To fix the issue in the struct source code, I first wanted to rewrite Hash128 to have an explicit union-like layout:
[FieldOffset(0)] uint m_u32_0;
[FieldOffset(4)] uint m_u32_1;
[FieldOffset(8)] uint m_u32_2;
[FieldOffset(12)] uint m_u32_3;
[FieldOffset(0)] internal ulong u64_0;
[FieldOffset(8)] internal ulong u64_1;
However, the type is used by Unity’s native code too, so it goes through some magic bindings/marshalling codegenerator which doesn’t seem to support explicit struct layout.
Instead, I decided to use 64-bit fields as the actual data backend. 32-bit fields were not used anywhere in the code anyway:
public Hash128(uint u32_0, uint u32_1, uint u32_2, uint u32_3)
{
u64_0 = ((ulong)u32_1) << 32 | u32_0;
u64_1 = ((ulong)u32_3) << 32 | u32_2;
}
public Hash128(ulong u64_0, ulong u64_1)
{
this.u64_0 = u64_0;
this.u64_1 = u64_1;
}
internal ulong u64_0;
internal ulong u64_1;
This actually makes the rest of the managed code even smaller and simpler. Amazing!
Now the output assembly of the constructor:
10abd40: 01 08 00 a9 stp x1, x2, [x0]
10abd44: c0 03 5f d6 ret
Fantastic, just storing a pair of registers to the address pointed by this.
The tests are green now, the NDK upgrade is good to go!
Follow-up
Having fixed the Hash128 implementation (which was a good change regardless), I was bitten few more times by the same issue when clang interprets UB like the above (unsafe pointer manipulation) in a way that’s not what you’d expect. One of them was a Burst test which compared some math results compiled by Burst and IL2CPP, and the IL2CPP result was incorrect. A more permanent fix on the compiler side was kindly suggested by our friends at Arm, and it is the following clang switch: -mllvm --dse-memoryssa-defs-per-block-limit=0.
I enabled this fix for Android only, but another clang-based platform exposed the same issue after upgrading to clang 12+. I can’t tell what’s the exact clang version which started behaving like this, but the workaround helped.
Can’t blame the compiler, it’s just how the Undefined Behavior rules work. Ideally, avoid this UB in your code, or deal with it!